You're viewing an archived page. It is no longer being updated.
Appendix: Sapphire/Slammer Worm - Impact on Internet Performance
René Wilhelm / New Projects Group / RIPE NCC
7-February-2003
Introduction
On the morning of 25 January 2003, the Sapphire worm (aka "SQL slammer") was released on the Internet. Abusing a vulnerability in Microsoft SQL server it multiplied itself rapidly and soon spread out over networks worldwide. From news headlines and activity on mailing lists it was clear the attack had an impact on the Internet's performance. The RIPE NCC Test Traffic Measurements service [1] is in a unique position to provide some quantitative insight in that impact, as we measure key Internet performance parameters[2], defined by the IETF ippm group, on 24/7 basis. We analysed the data collected on January 25 and present results here.
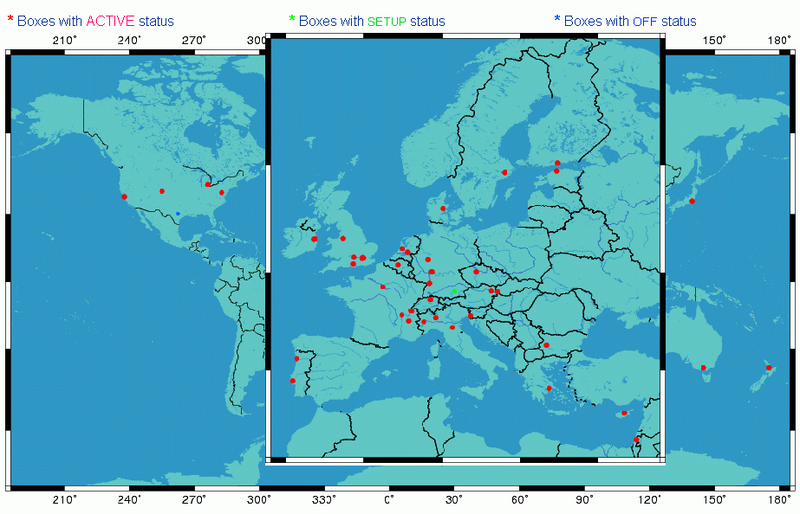
Figure 1. Location of the TTM test-boxes; those active in themeasurement process are marked red.
The data sample
At the time of the worm attack, we had measurement probes (test-boxes) installed and active at 49 different sites (figure 1). For this analysis, we limited ourselves to one box per organisation and did not investigate data collected by other boxes at a site. Each box sends test-traffic packets to each other box, resulting in 49 x 48 = 2352 measurement relations. For each measurement relation we send 120 packets per hours, and perform regular traceroute measurements as a best estimate on how packets traveled through the Internet. To get an idea of the impact of the worm, we marked traffic from one box to another box as affected by the attack when either of the following conditions applied:
- one-way delays were significantly higher or more spread out in the six hour period following the attack (as compared to the six preceding hours). Most of these paths were also marked by the TTM alarm messages.
- total packet loss in the hours following the attack exceeded 1% (and was close to zero in the hours before)
The result of these cuts: 922 (40%) relations marked affected, 1430 (60%) marked unaffected.
A visual inspection of the data revealed a range of problems:
- delays were more spread out, but no packets were lost
- delays greatly increased, but similar spread around mean as before, no packets were lost
- increased delays and packet loss (ranging from 10% to 80%)
- complete blackout (100% packet loss)
- any combination of the above
In addition, we observed quite some asymmetry: delay and loss patterns in one direction being very different in the reverse direction. Several annoted example plots are discussed below.
Next we looked at the distribution of problems over the test-boxes: i.e. which hosts were seen as the sender and which were seen as the receiver in the affected measurement relations. Surprisingly, we found that 20% of the test-boxes accounted for 86% of the affected measurement relations: Eight boxes had problems in relation to all other test-boxes both for incoming and outgoing traffic, which indicates trouble at or close to the hosting site. An additional 2 boxes had all of their incoming traffic affected. These sites were possibly safe from infection but suffered from overloaded input queues. It is also possible that asymmetric routing simply bypassed the spots that troubled the test-traffic being send to the host.
The 14% (130 of the initial 922) remaining cases were mixed situations, where neither the sending nor the receiving host had problems with all incoming/outgoing traffic. A sizable fraction is made up by measurement relations that just passed the selection criteria, typically packet loss fluctuates around the 1% mark, removing some relations from the sample while leaving others in it.
The rest are special cases where either or both the sending and receiving sites have multiple connections to the interned only one of which is affected by the worm. A nice example of this is the test-box located in Menlo Park, California: the hosting organization gets connectivity from two upstream providers, all test-traffic leaving or arriving at the site via one provider is affected by the attack (packet loss), traffic flowing via the other provider is all unaffected.
Conclusions
Looking at all data we can conclude that the Internet did not come to a global meltdown; 60% of the measured relations do not show any sign of deterioration. This indicates most backbone links were fine, the problems were localized in edge sites or their immediate upstream provider.
We also observed a lot of asymmetry in the data, which again proves that one-way measurements are crucial for understanding Internet performance.
Individual plots
In this appendix we present some TTM delay plots that illustrate the effects of the worm attack on our end-to-end test traffic measurements. The various components of the TTM plots are described in detail in [3]. The important parts for this analysis are the bottom right graph which plots fraction of packets arrived vs. time, and the top left graph, where black dots plot results of delay measurements vs. time and red dots are a measure of the number of hops observed in the traceroute measurements. All these plots show the time interval 00:00 - 12:00 UTC of January 25.
Note: these inlined images are reduced in size, click on any of them to view them with all detail.
RIPE NCC - Torino (IT)
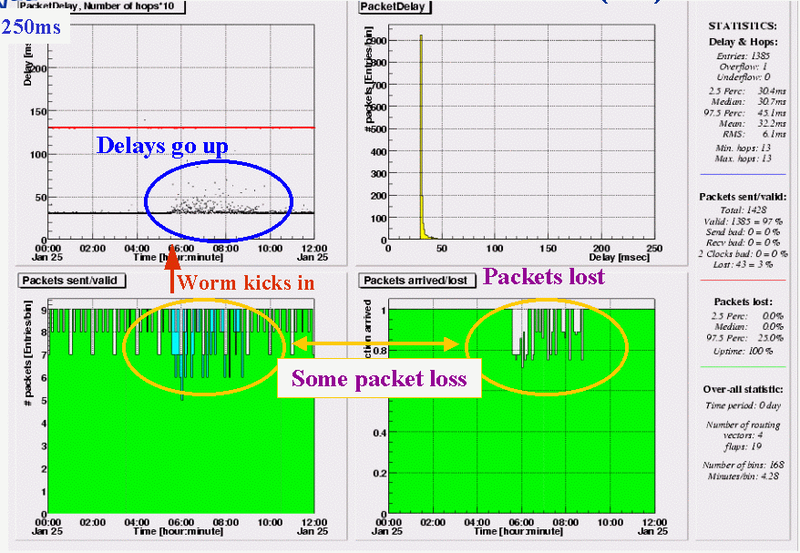
Delays from the (Amsterdam based) RIPE NCC to a host in Torino, Italy are more spread out, for a period of almost 3 hours, starting at or very shortly after 5:30 UTC. At the same time, we see packets getting lost, a total of 43 (12%) out of the 357 send in these three hours.
RIPE NCC - Ann Arbor, MI (US)
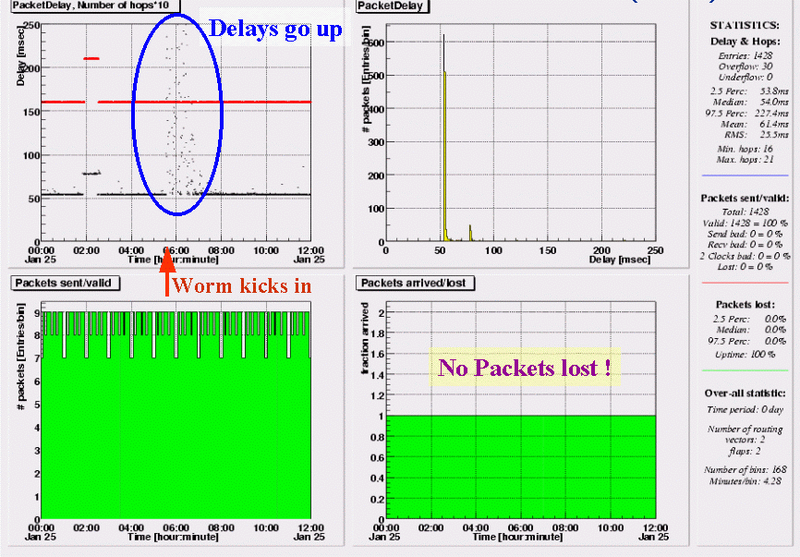
Delays to Ann Arbor are much more spread, reaching peaks of 250ms, during the 2 hour period following start of the worm. But unlike the previous case, not a single test-traffic packet is lost. The temporary increase in delays around 02:00 is caused by a change in routing; as indicated by the red line, the new path has 21 instead of the usual 16 hops.
Ann Arbor, MI (US) - RIPE NCC
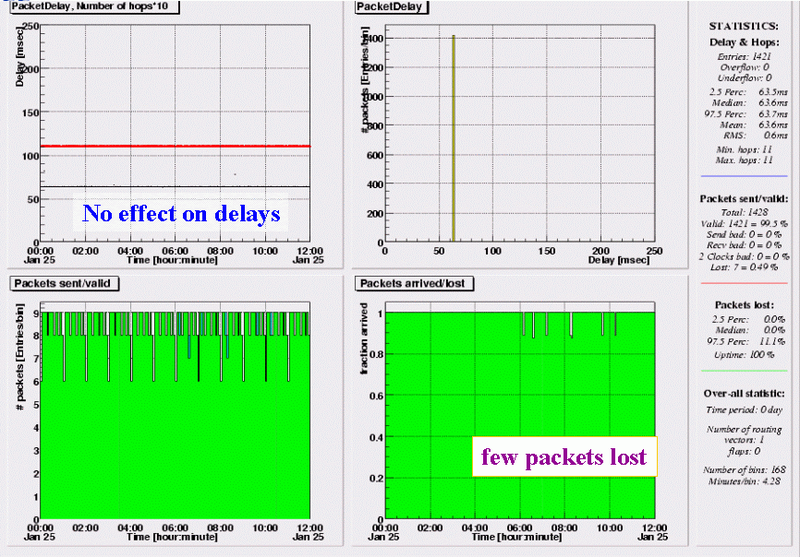
The equivalent plot for one-way delays in the reverse direction. In this case the delays are stable, but 7 packets (1%) are lost between 05:30 and 10:30.
RIPE NCC - Paris (FR)
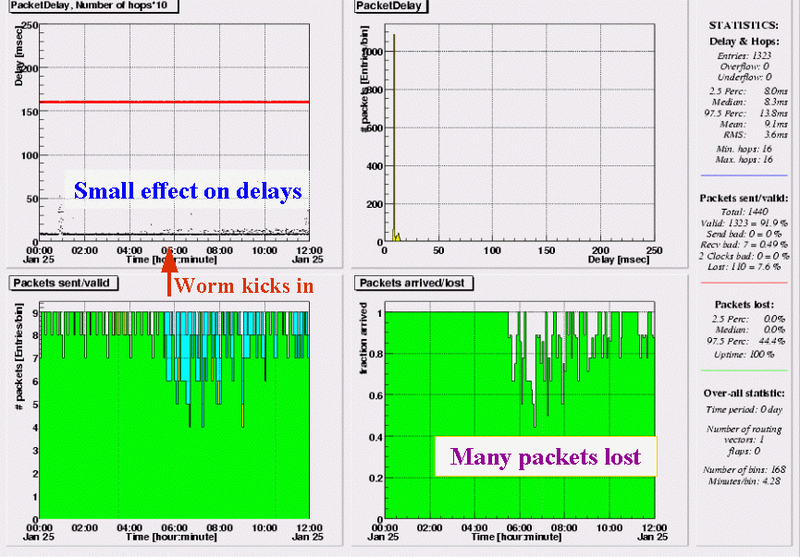
From the RIPE NCC to a site near Paris, effects on delays are small but we observe quite some packet. This peaks in the first hour of the attack, but lasts until the afternoon. In total about 14% lost between 5:30 and 12:00 UTC.
Paris (FR) - RIPE NCC
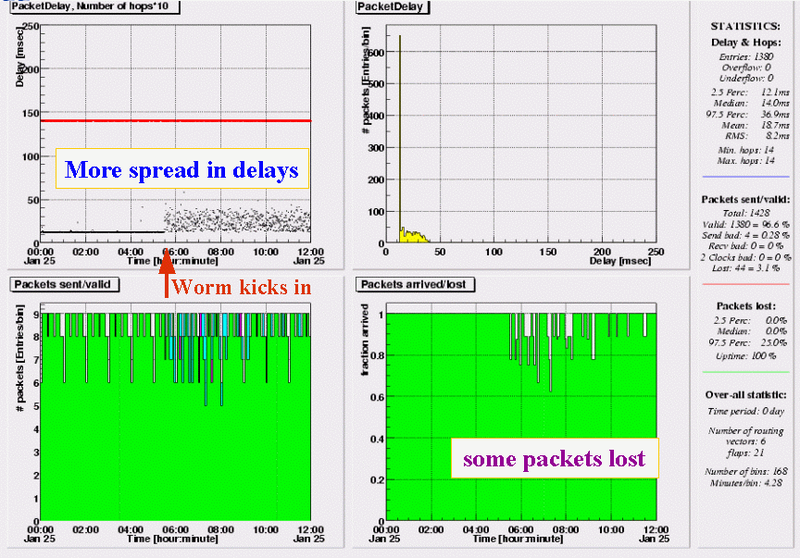
In the reverse direction, less packets are lost (6% in 6.5 hours), but delays are almost evenly spread in a 25ms range. We see this pattern in all outgoing test-traffic from this box, which indicates the problem is at or close to the hosting site. Further investigation learned us, this situation lasted until 19:00 UTC, with an addional 2% packets lost between 12:00 and 19:00.
RIPE NCC - Nicosia (CY)
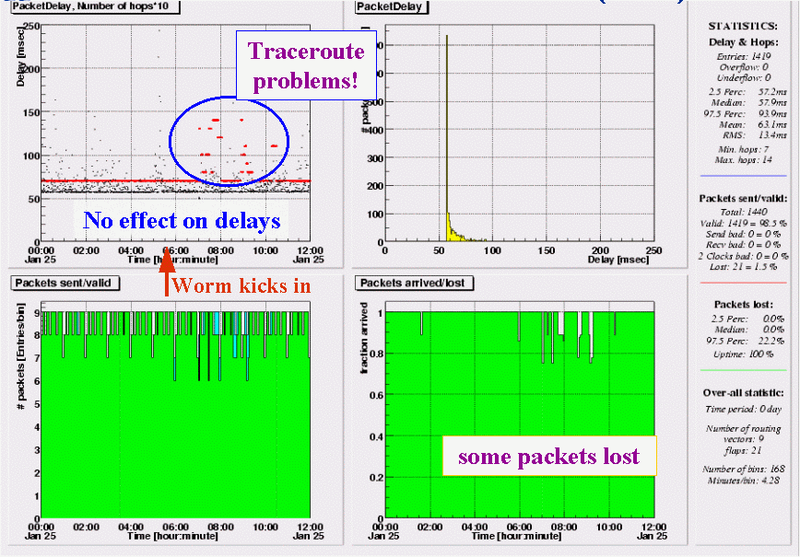
On traffic from RIPE NCC to Cyprus, the worm attack does not have much effect; delay pattern does not change and only 20 packet (3%) are lost in a five hour period. However, what is striking in this graph is the scattered pattern in the red points that plot the number of hops seen in traceroutes over time. As test-traffic itself does not have much problems, this most likely indicates a problem in the return path, the ICMP time exceeded messages not making it back to the NCC.
Nicosia (CY) - RIPE NCC
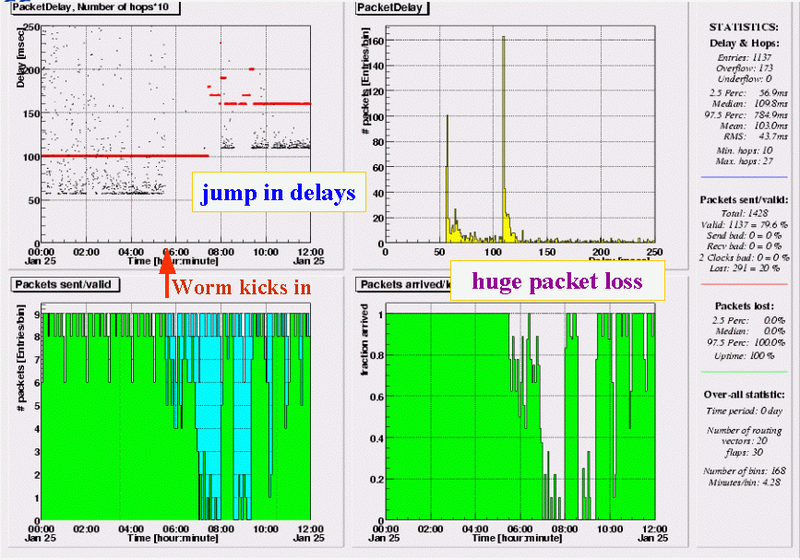
As already suspected, the reverse direction Cyprus - RIPE NCC, is very troubled. As soon as the attack starts, delays jump up, going off scale until 08:00 with a 97.5 percentile of 785ms. About 1.5 hours into the attack, the packet loss reaches levels close to 100%. At 08:00 things seem to stabilize, though a change in routing (red dots, settle at 16 instead of 10 hops) results in 50ms higher delays. However, at 08:30 packet loss goes up again to almost 100% for another hour.
RIPE NCC - Tokyo (JP)
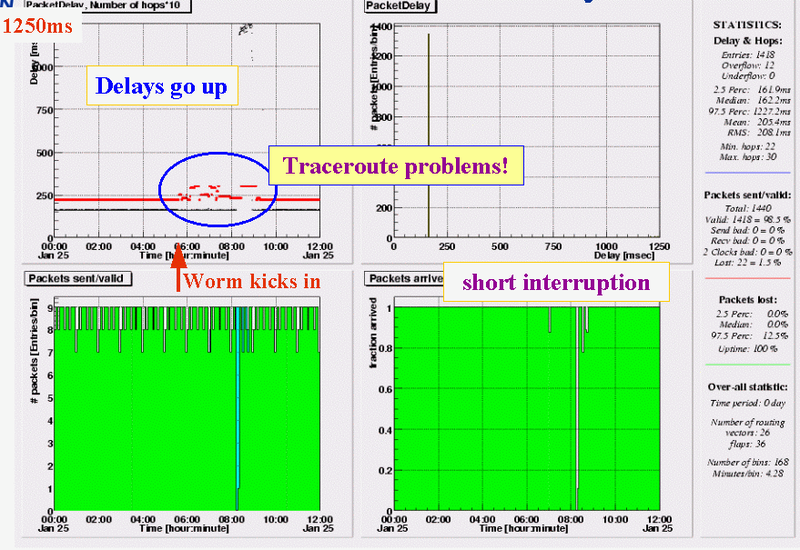
At first glance, the traffic from RIPE NCC to a site in Tokyo seems ok; at the start of the attack no changes seen in delay and loss patterns. Traceroutes, however, immediately become unstable, indicating a problem in the reverse direction. More than 2.5 hours into the attack, things suddenly turn for the worse: first there is a 15 minute period where all packets are lost, then delays sky rocket to a level of ~1250ms (remember this is one-way!) Around 09:00 delays return to the usual value.
Amsterdam (NL) - Tokyo (JP)
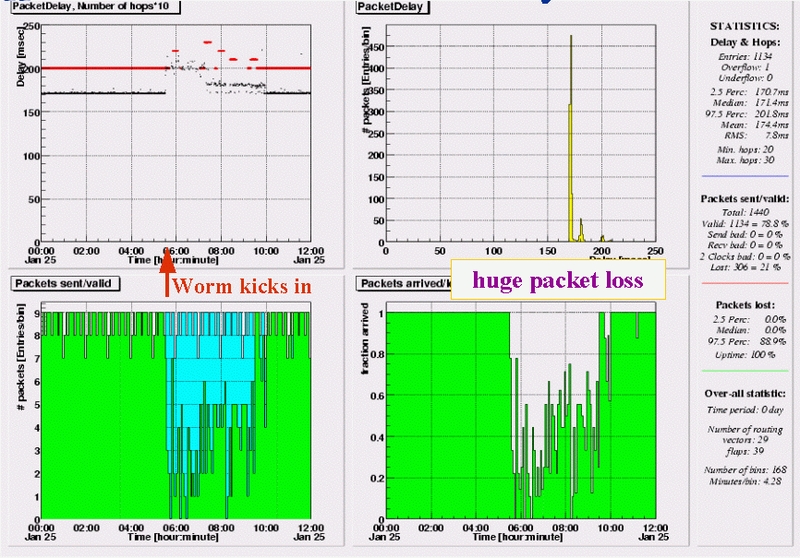
Test-Trraffic from another site in Amsterdam, only a few hundred meters away from the RIPE NCC's test-box, show a very pattern. From the moment the attack starts, we see huge packet loss and a 30ms increase in delays. Since only a few measurement relations from this Amsterdam site are affected by the worm, the difference in loss & delay patterns compared to traffic originating at the RIPE NCC indicates problems are either on the backbone path or in the first (different) hops in Japan. The network segment hosting the box in Japan certainly does not have problems with incoming traffic.
Tokyo (JP) - Amsterdam (NL)
Delay and loss patterns from Tokyo to both RIPE NCC and the other Amsterdam location are very similar. The same pattern can be seen in data from to Tokyo to all other test-boxes. This indicates the problems are in the hosting site, or in the first hops of their upstream provider (up to the point where the TTM traffic forks off in different directions).
LINX (London) - Frankfurt (DE)
From the London Internet Exchange to a site in Frankfurt, Germany, the one-way delays jump within a few minutes from less than 20ms to almost 900ms. For 6 hours delays tay at this high level, with only an occasional packet coming through faster; packet loss in this period is negligible, less than 1%. At 11:30 delays fall back to the old level just as fast as they went up around 05:30.
RIPE NCC - London (UK)
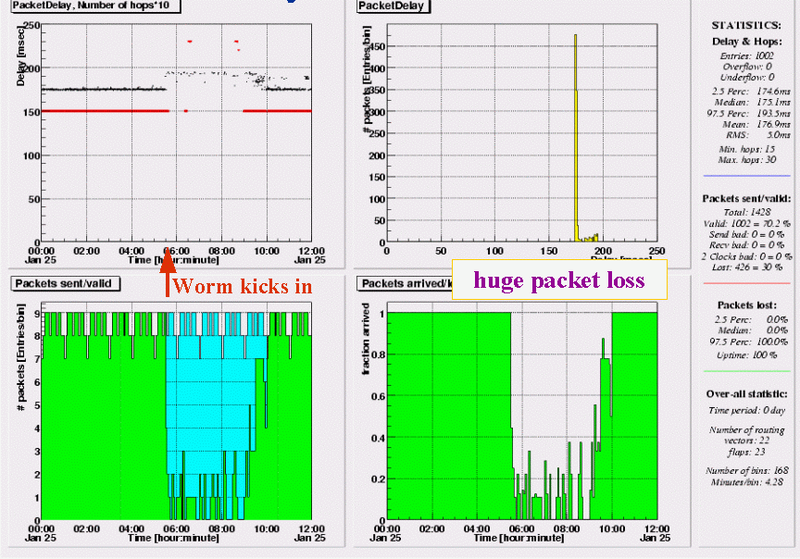
Traffic from the RIPE NCC to a service provider in London sees 100% packet loss from the very moment the worm attack starts. In the next 5 hours only an occasional packet makes it through. This pattern is seen in all measurement relations towards this site, for 2 out of 48 sending sites the situation is even worse, 20-30 minute periods with 100% packet loss also occurring after 10:30.
London (UK) - Southampton (UK)
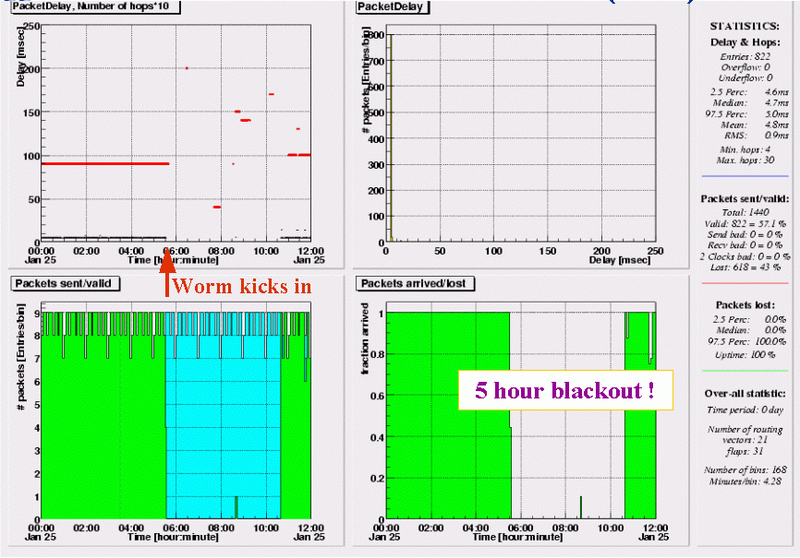
For measurements initiated by this London based service provider, the worm has equivalently bad impact; between 5:30 and 12:00 almost all packets are lost. As the same loss pattern is seen in traffic to all other 48 destinations, the problem is at or close to the hosting site. Customers of this ISP were without Internet connectivity for the entire saturday morning.
Dublin (IE) - Hamiltion (NZ)
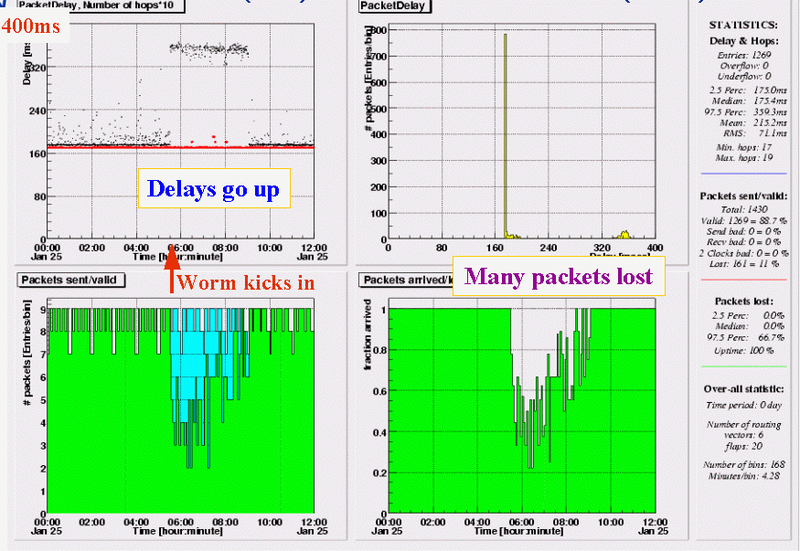
Hamilton (NZ) - Dublin (IE)
Measurements between the test-box in New Zealand and all other boxes show very asymmetric behavior: all incoming traffic is fine, all outgoing traffic sees delays jumping to an increased level (from 175ms to 360ms in the case of the Dublin box) from 05:30 to approximately 09:00. The increased delays are accompanied by a lot of packet loss.
Denver, CO - Melbourne (AU)
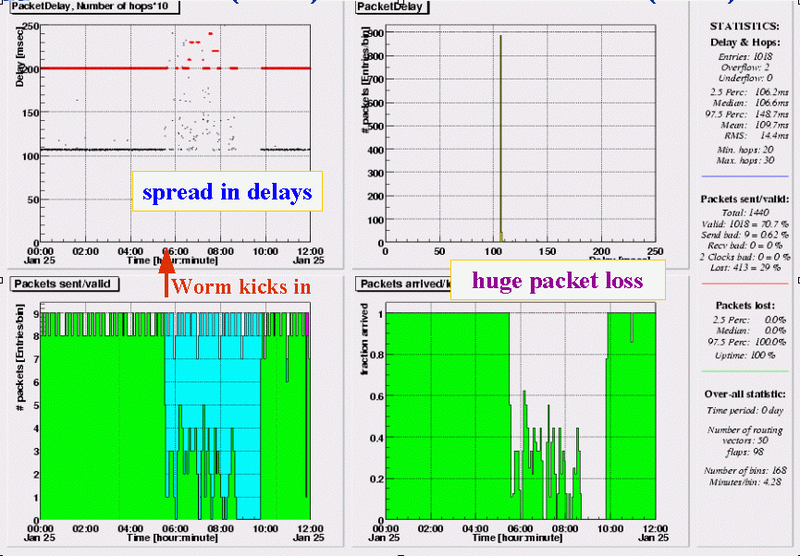
Delay and loss patterns for the box in Australia show a combination of effects seen in other measurement relations. From 05:30 to 08:45 a lot of packets are lost (60 - 80%), the packets which do make it through have an increased spread in delays; from 08:45 to 09:45 all packets are lost. As practically identical patterns are seen in all other measurements from and to this box (including those with the test-box in `nearby' New Zealand) the problems are in the hosting site or the Australian upstream provider(s).
Denver, CO (US) - Menlo Park, CA (US)
From Denver to Menlo Park we see delays hardly affected, but four periods with packet loss. Between 5:45 and 6:15 about 60% of the packets are lost, the intervals between 08:00 and 12:00 feature 100% loss. Further analysis of the data shows the site in Menlo Park has two upstream providers. Test-traffic coming into or leaving the site via the first provider has loss patterns similar to the above, traffic flowing via the second provider is not affected at all.