You're viewing an archived page. It is no longer being updated.
Analysis
Our analysis focused on publicly available data from the following RIPE NCC services:
Routing Information Service (RIS)
The RIS collects Border Gateway Protocol (BGP) routing information messages from 600 peers at 16 exchange points in near real time. Results are stored in a database for further processing by tools such as BGPlay, a visualisation tool. Three times a day, the route collectors take snapshots of their respective Routing Information Bases (often referred to as "RIB dumps").
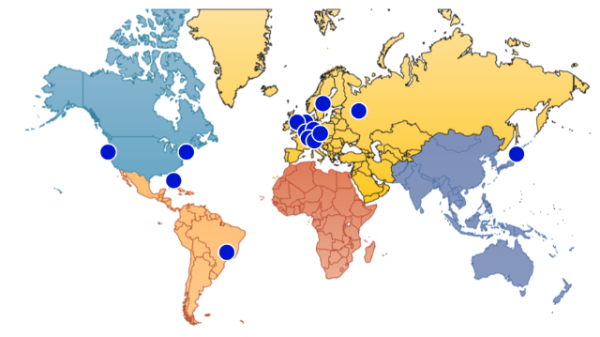
Location of RIS Remote Route Collectors (RRCs)
Test Traffic Measurements (TTM)
TTM measures key parameters of connectivity between a site and other points on the Internet. Traceroute vectors, one-way delay and packet-loss are measured using dedicated measurement devices called "test-boxes". Configured in an almost full mesh (that is, fully inter-connected), the TTM test-boxes continuously monitor end-to-end connectivity between the hosting sites.
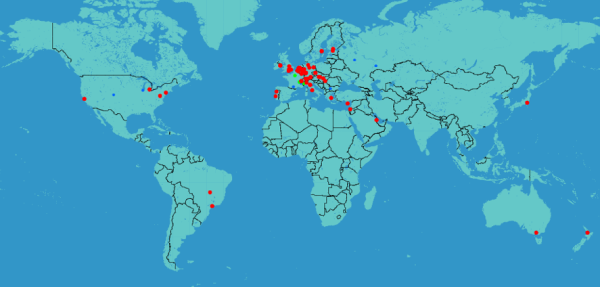
Location of TTM nodes
DNS Monitoring Serive (DNSMON)
DNSMON provides a comprehensive, up-to-date overview of the service quality of root name servers, as well as participating country code and generic Top Level Domains (TLDs). Using the infrastructure of TTM probes, DNSMON measures query response times to 196 name servers. Therefore DNSMON provides another perspective on possible effects the cable outages may have had on the Internet .
In the sections below we discuss the results of each of these services. However, we want to stress that the bigger picture only emerges when we combine the knowledge gained in the separate fields. Where BGP looks at routing information, active measurements by TTM and DNSMON provide a glimpse on how networks performed during the outage. Results from one service thus help us to understand results from the others.
BGP Overall
The impact of the outages on BGP largely depended on how the cables were used in peering sessions.
- When peering between a Middle East-based provider and their transit in the West was established over the cables, or when the peering depended on receiving reachability information over the cable through some interior routing protocol, the sessions were dropped immediately after the failure. If the provider had no other way to route his IP traffic, the networks disappeared from the global routing tables at 04:30 or 08:00 (UTC) respectively.
- In cases where peering happens in the West, or where Middle Eastern networks are announced statically in the West, the sessions would not be expected to go down immediately after a cable failure. Instead, visibility in BGP would depend on manual network administrator action. This explains why some networks disappeared from the global routing tables several hours after the cable failures.
Where backup paths did exist, BGP explored and used them. We observed significant changes in the peering usage between larger transit providers. However, due to limited bandwidth and increased demand on the backup paths, sessions weren't always stable. In those cases BGP had difficulties converging on alternate topologies.
Prefix Counts
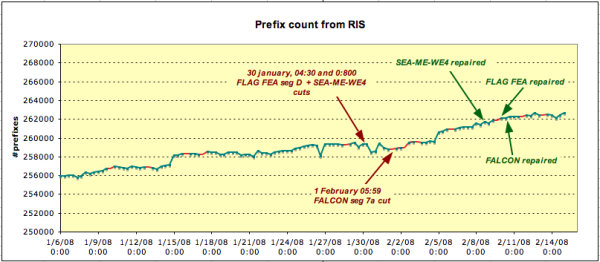
The number of prefixes seen in RIS is an indication of global network reachability. If a prefix cannot be seen and is not covered by an aggregate, it is likely the network in question has become unreachable. Therefore, total prefix count is a good starting point for BGP analysis. Using the data from the eight hourly RIB dumps, we graphed the total number of prefixes seen by RIS over time. The result does not show any clear drop or increase in the amount of prefixes near the known failure and recovery events. On a global scale, the cable outages only affected a small percentage of all networks.
Location of TTM nodes
However, when we assign country codes to each prefix, based on the information from RIR delegation statistics, we see various countries with significant reductions in the number of announced prefixes. The graph below compares, for each country, the number of prefixes seen in RIS over time with the number of prefixes visible at 00:00 (UTC), 30 January 2008. This gives an indication of the impact of the cable failures on network reachability in BGP.
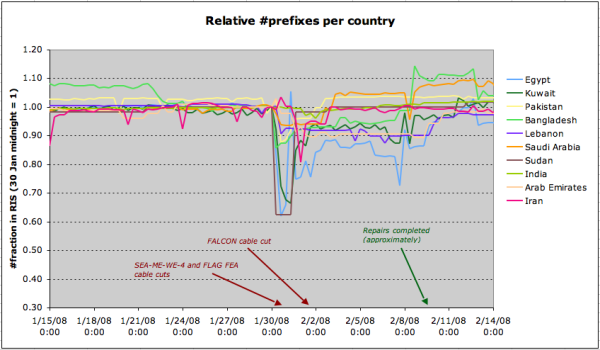
Relative prefix count for most affected countries
Egypt, Sudan and Kuwait were amongst the hardest hit, with drops of up to 40% in prefix visibility.
Analysis of AS Path Changes
Next we looked at changes in Autonomous System (AS) paths. In relation to the cable cuts, the two main reasons for change are:
- Networks disappearing from the routing tables (this reduces the total number of AS paths)
- Networks rerouted on IP level (when the preferred transit is unavailable, BGP will try backup paths; these are likely to be longer)
Again starting from the RIB dumps, we compared consecutive dumps from the largest RIS route collector, RRC03, and determined the changes in distinct AS paths. Because AS path changes capture more of the event, we thought that graphing global level changes would clearly and unambiguously show when the cables snapped. That hypothesis did not hold. Although the cable cuts triggered a flux of changes, it is not the only such signal in a one month time period. Other events, either in BGP or related to RIS collector peers, triggered comparable levels of change.
As with the prefix counts, the correlation with the cable outages only becomes clear when we restrict the comparison to those AS paths where one or more of the constituent AS Numbers is registered to the region by an RIR:
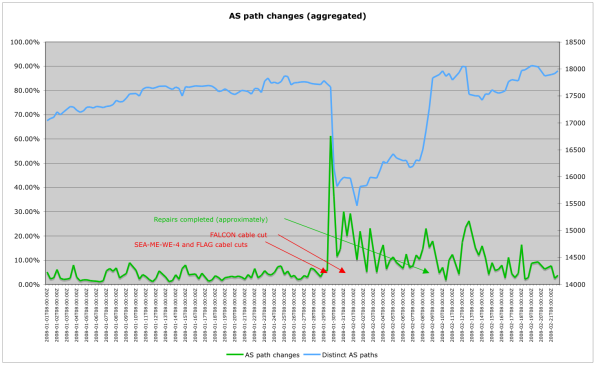
AS path changes (Aggregated)
The above image shows the total number of distinct AS paths and the relative amount of change in distinct AS paths associated with the region. The changes seen align quite well with the event timeline.
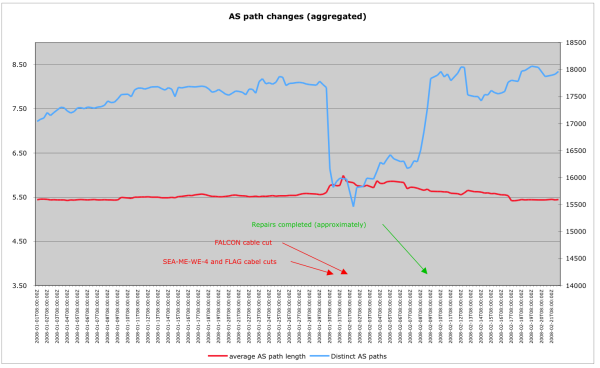
AS path changes (Aggregated)
This image again shows the total number of distinct AS paths associated with the region, this time augmented with the average length of those AS paths. As expected, the average AS path length increases around the time period of the cuts.
Analysis of BGP Dynamics (Case Studies)
To better understand the routing dynamics caused by the fibre cuts, we analysed some specific cases in detail, as samples of different patterns in routing changes:
The fibre cuts meant that some prefixes were unreachable for a significant period of time. Case Study 1 shows that the link between AS20484 (Yalla Online, Egypt) and AS8452 (TEDATA, Egypt) experienced a major network event; the prefixes usually routed through this link either were unreachable or changed their routes for most of the period.
On the other hand, some prefixes did not change their routes. Case Study 2 demonstrates that the network hosting TTM box 138 (in Bahrain) was rerouted at sub-IP level. Thus its BGP routing didn't change, while the traffic experienced some major delays and packet loss; evidently, the backup bandwidth is much less than the original path over SEA-ME-WE4.
Other prefixes changed their routes for a significant period of time. Case Study 3 illustrates how AS17641 (Infotech, Bangladesh) changed one of its upstream providers.
Finally, we observed prefixes which experienced long periods of BGP instability. Case Study 4 shows how OmanTel triggered over 10,000 BGP update messages in RIS in a 90 hour (3.5 day) time period. Routes were flapping constantly for several peers, making it questionable whether BGP path exploration always converged.
Further details on each of these case studies can be found in the appendix.
Affected BGP Peerings
During the fibre cuts, we observed significant changes in BGP peerings usage. Some peerings went down and were not used again before the repair of the fibre(s). Others were selected as backup paths, which meant that their usage exploded. The metric we used to approximate the usage of a BGP peering between two Autonomous Systems is the size of the sets of all the prefixes routed through the peering, as seen by all the available collectors at once.
From our data sources, we extracted the BGP peerings which, from 16:00 (UTC), 29 January to 08:00 (UTC), 3 February, matched the following criteria:
- Carried, at some time, a significant number of prefixes (that is, more than 50 distinct prefixes) as observed from all the available collector peers
- Routed no traffic (that is, zero prefixes world-wide) for more than 12 hours
590 distinct BGP peerings involving 309 distinct Autonomous Systems matched the criteria described above. The ratio between the number of peerings and the number of Autonomous Systems suggests a high correlation of events.
As expected, AS15412 (FLAG Telecom) was one of the most involved Autonomous Systems, being present in more than 40 peerings. Other highly affected Autonomous Systems included AS4788 (TMNET, Malaysia), AS7575 (AARNET, Australia) and AS7473 (Singapore Telecommunications Limited), which were involved in more than 70 peerings overall.
The most affected AS was AS8966 (Emirates Telecommunications Corporation), which accounted for more than 100 peerings. From communications on the LINX-ops mailing list, we learned that AS8966 stopped advertising prefixes at the London Internet Exchange because of lack of capacity on back haul links. This meant that all peers at LINX explored alternative paths towards AS8966.
Note that the selection criteria for the peerings will give us the failing links, links which went down on purpose and links which were used for backup connectivity.
Backup Links
As shown in the following figures, some previously unused peerings suddenly began to route a large number of prefixes, probably due to the unavailability of other (preferred) routes.
Large sets of prefixes were rerouted and subsequently withdrawn within a few hours, thus BGP convergence likely slowed down.
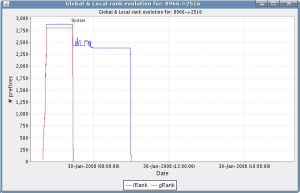 |
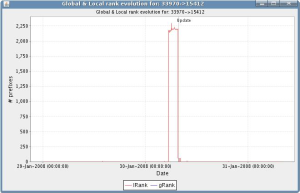 |
Left figure: More than 2500 prefixes were suddenly routed through the peering AS8966-AS2516 (Emirates Telecommunications Corporation - KDDI). This continued for a couple of hours.
Right figure: AS33970 (OpenHosting) temporarily routed a large set of prefixes through FLAG Telecom (AS15412). It took more than two hours to return to the previous usage level.
Failing Links
As expected, some of the peerings experienced a drop in the number of prefixes routed right after the faults.
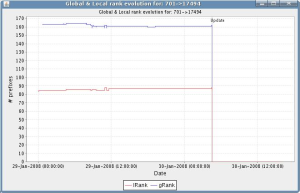 |
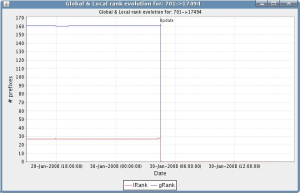 |
Left figure: The peering between AS701 (UUNet) and AS17494 (Bangladesh Telegraph and Telephone Board) dropped by over 100 prefixes.
Right figure: The AS701-AS17494 peering again, observed from a different collector peer. The local rank differs because the two peers see different numbers of prefixes with AS701 in their AS path. Obviously, the global rank evolution is the same as in the left plot (but note the slightly different time range on the x-axis).
Active Measurements
Test Traffic
Looking at statistics and plots published on the Test Traffic Measurement (TTM) website, we learned that from the approximately 75 active probes, only one had serious trouble as a result of the cable outages: node TT138, installed with 2connect in Bahrain, became unreachable from all other nodes at 04:30 (UTC) on 30 January.
After two and a half days, basic Internet connectivity was restored. However, the latencies and packet loss, especially for traffic going to Bahrain, were much higher. With peaks in one-way delay of 1.2 full seconds on 6 and 7 February, the network's performance would have been rather poor for End Users. Finally, in the evening of 8 February, when repairs to the SEA-ME-WE4 cable had been completed, latencies returned to normal conditions.
The graphs below show packet delay (black dots) and number of hops in traceroute (red lines and dots) to and from the RIPE NCC over time. Similar patterns were seen in plots to and from other TTM probes.
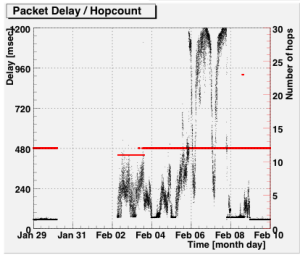 Delay from tt01 to tt138 |
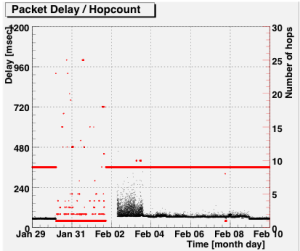 Delay from tt138 to tt01 |
As illustrated in BGP Case Study 2, detailed in the appendix to this document, the BGP routing information was relatively stable during this entire period. Even after the site became unreachable, BGP continued propagating routing information for 2Connect's prefix. We see this reflected in the tracreoutes conducted by TTM: right after the cable cut, traceroutes from TT01 did start tracing the route to TT138, but replies stopped coming in after the eighth hop, in AS6453:
Traceroute results from Amsterdam to Bahrain on 30 January:
Before the cable cut:
| hop | IP | origin AS |
|---|---|---|
| 1 | 193.0.0.238 | 3333 |
| 2 | 195.69.144.110 | 1200/31283/30132/12989 |
| 3 | 4.68.120.15 | 3356 |
| 4 | 4.68.110.226 | 3356 |
| 5 | 80.231.80.5 | 6453 |
| 6 | 80.231.80.30 | 6453 |
| 7 | 195.219.195.6 | 6453 |
| 8 | 195.219.189.106 | 6453 |
| 9 | 80.88.244.33 | 35313 |
| 10 | no response | |
| 11 | 80.88.240.121 | 35313 |
| 12 | 80.88.240.14 | 35313 |
After the cable cut:
| hop | IP | origin AS |
|---|---|---|
| 1 | 193.0.0.238 | 3333 |
| 2 | 195.69.144.110 | 1200/31283/30132/12989 |
| 3 | 4.68.120.15 | 3356 |
| 4 | 4.68.110.226 | 3356 |
| 5 | 80.231.80.5 | 6453 |
| 6 | 80.231.80.30 | 6453 |
| 7 | 195.219.195.6 | 6453 |
| 8 | 195.219.189.106 | 6453 |
| 9 | no response | |
| 10 | no response | |
| 11 | no response | |
| 12 | no response | |
| ... | ||
| 30 | no response | |
Before the cut, traceroute entered the destination AS at hop 9. The return-trip times (RTT) returned in manual tracreoutes to TT138 suggest this hop is located in Western Europe. Interestingly, a traceroute to the hop 9 address, 80.88.244.33, returns with last hop IP 195.219.189.62. Because this address is from a network registered in RIPE Database as LONDON-TGB/Teleglobe's backbone, we conclude this network node is a Teleglobe router in London configured with IP addresses from Bahrain-based 2Connect. Teleglobe are also likely to be the ones injecting the 80.88.240.0/20 prefix into BGP on behalf of AS35313. This is done irrespective of the state of the link(s) to Bahrain, presumably using statically configured routes.
When basic end-to-end connectivity had been restored on 2 February, traceroutes to Bahrain showed a slightly different path in the final three hops. However, traceroutes from Bahrain don't show any change. We conclude that there was a temporary recovery from the SEA-ME-WE4 cut, created by Teleglobe setting up a different data link for IP traffic to Bahrain, and possibly augmented by a minor internal IP level change in Bahrain.
DNSMON
Because the DNSMON service uses the TTM infrastructure, problems with the Bahrain node also showed up here:
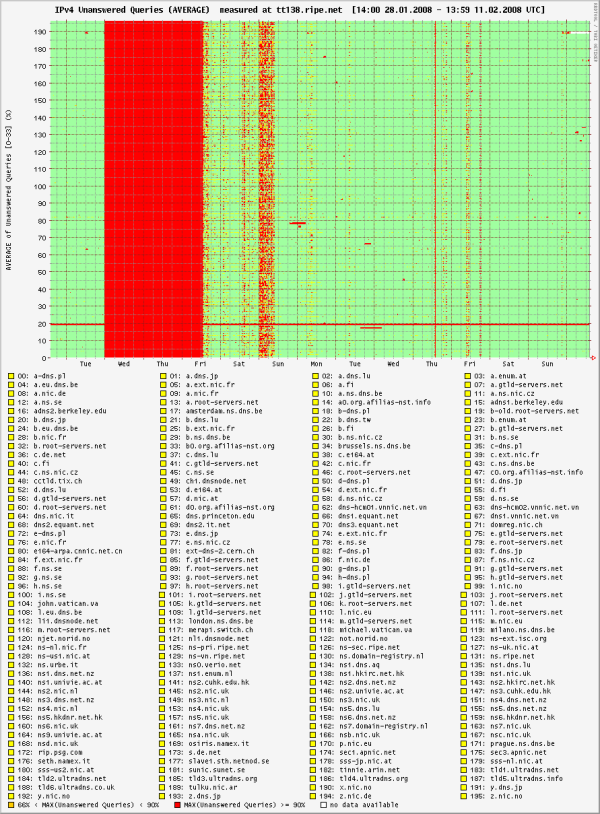
DNSMON graph for TT138. Each horizontal line corresponds to one monitored name server. Red dots mark unanswered queries
The plot shows that none of the 196 monitored name servers answered queries from TT138 in the period for which TTM already reported problems. This is further evidence that, despite the routing information carried in BGP, the ISP was actually cut off from most of the Internet for two and a half days.
At first glance the list of monitored name servers and TLDs in the graph suggests DNSMON had no measurement targets in the Middle East or South Asia. However, this is not completely true. Some of the name servers are implemented with anycast, with a number of servers connected at different locations worldwide, all using the same global IP address. Which of these is actually used by a client depends on BGP policies, which affect how the name server's network is announced and received at various places.
The K-root name server, operated by RIPE NCC, is one example of an anycast server. Three instances are deployed in the region affected by the cable cuts: two of these, with Qtel in Doha (Qatar) and with Emix in Abu Dhabi (United Arab Emirates), are intended as local nodes; routing announcements for these K-root sites should not be propagated by the local peers to the global Internet. The third one in Delhi, India, is a global node; this means the peers can pass the announcements to their upstreams, thereby making the node an option to choose from for anyone who receives the route to Delhi.
In normal reporting DNSMON does not show which anycast instance was used by the probes. However, the raw data also includes queries into the identity of the server. Using this raw data, we looked for correlations between k.root-servers.org instance changes on each DNSMON probe and the known cable outage events. Of the 75 probes, only four show strongly correlated and unexpected correlations: on 30 January at 05:25 UTC, less than 1 hour after the SEA-ME-WE4 cut, the test-boxes hosted by AMS-IX all switched to using the local node hosted by EMIX in Dubai, UAE. The situation lasted for more than seven days, until 20:00 (UTC), 5 February. These observations provide positive confirmation that EMIX was reachable from Amsterdam during the entire cable outage period. However, the highly increased response times for the DNS queries do indicate congestion on the backup links. Also, the unfortunate leaking of the EMIX local node route announcements caused deteriorated service for those who received and preferred that route over a global node's announcement.
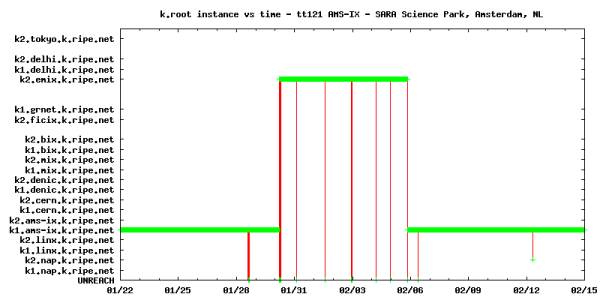
Results from DNSMON probe tt121: k.root instance used in a two-week time interval.
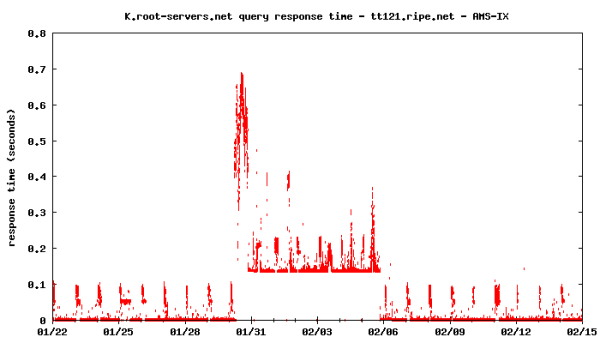
Results from DNSMON probe tt121: k.root query response time for TT121 in the same period.