Transition Mechanisms
Transition Mechanisms allow:
- IPv6 devices to communicate with each other over an IPv4 network (“tunneling”)
- IPv6 devices to communicate with IPv4 devices (“translation”)
Transition Mechanisms discussed in this article include:
- 6in4
- 6to4
- 6rd
- DS-lite
- Nat64 and DNS64
- 464XLAT
When IPv6 was developed in the 1990s as the new Internet protocol to replace IPv4, which was already running out at that time, it was assumed that the transition would happen relatively swiftly and there wouldn't be a long period when both protocols would be used extensively at the same time.
As we now know, this assumption was wrong – and for the foreseeable future, both protocols will have to be used side by side until IPv6 is more widely deployed.
However, this poses a challenge, because IPv6 was not developed to be backward compatible with IPv4. This means that an IPv4 device and an IPv6 device cannot communicate directly with each other without some mechanism or device in between. These mechanisms are called “transition mechanisms”
1. Tunneling and Encapsulation
To connect IPv6 devices over an IPv4 network, an IPv6 tunnel over the IPv4 network is used.
The IPv6 packet originating from the sender's IPv6 device is encapsulated at the entry node of the tunnel, where it gets an additional IPv4 header and then travels through the IPv4 network as an IPv4 packet. At the tunnel exit node, the IPv4 header gets removed (decapsulated) and the package reaches the destination IPv6 device as an IPv6 packet.
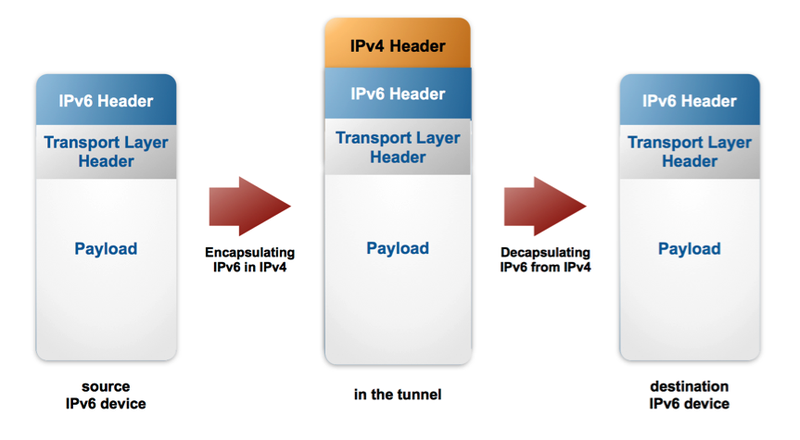
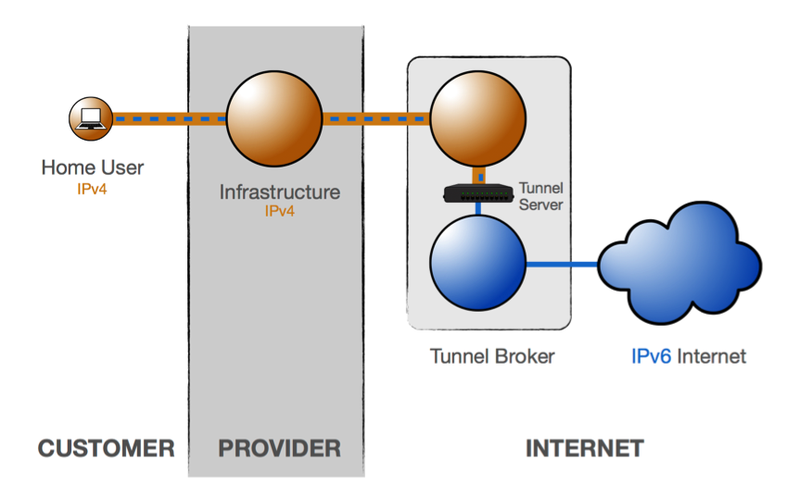
6in4
6in4 uses tunneling to encapsulate IPv6 traffic over explicitly, manually configured IPv4 links. The IPv4 tunnel endpoint address is determined by configuration information on the encapsulating node.
This is the simplest tunneling mechanism – a manually configured tunnel towards a fixed tunnel broker like SixXS or Hurricane Electric. It is reliable and stable, but not scalable – it's not suitable for a provider deploying IPv6 for a large customer base. However, this method is especially suitable for an individual home user to set up IPv6 connectivity via a tunnel broker, if his provider doesn't provide IPv6 connectivity.
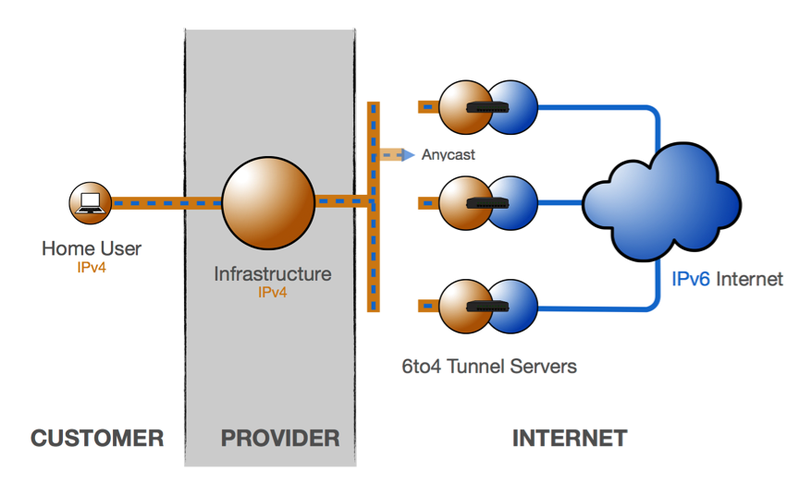
6to4
6to4 is generally not used anymore. It is a tunneling technique that solved the disadvantage of the 6in4 tunneling technique not being scalable. A provider could use it to roll out IPv6 deployment to a large customer base. However, 6to4 has a major drawback: it can cause unacceptably long latencies, resulting in negative user experiences.
6to4 uses only the 2002::/16 IPv6 prefix and the 192.88.99.0/24 IPv4 prefix for all the tunnel endpoints (tunnel entry and exit nodes) anywhere in the world.
When a source 6to4 IPv6 device (which is often the tunnel entry point as well) wants to communicate with a destination IPv6 device, the tunnel entry point can find a tunnel exit point automatically by anycasting the prefix – no tunnel configuration is necessary. However, the 6to4 end user device needs a public IPv4 address.
The IPv4 tunnel exit point is embedded in bit numbers 17-48 of the 6to4 IPv6 address. So the tunnel entry point automatically takes the IPv4 address of the tunnel exit point from the IPv6 address of the destination.

A schematic representation of the different parts of a 6to4 IPv6 address:

Since the tunnel endpoints are anycasted, the user has no control over which tunnel endpoint will be used. The return traffic can also choose another tunnel entry point, which can create asymmetrical routing, long latencies, and unacceptably long waiting times for users.
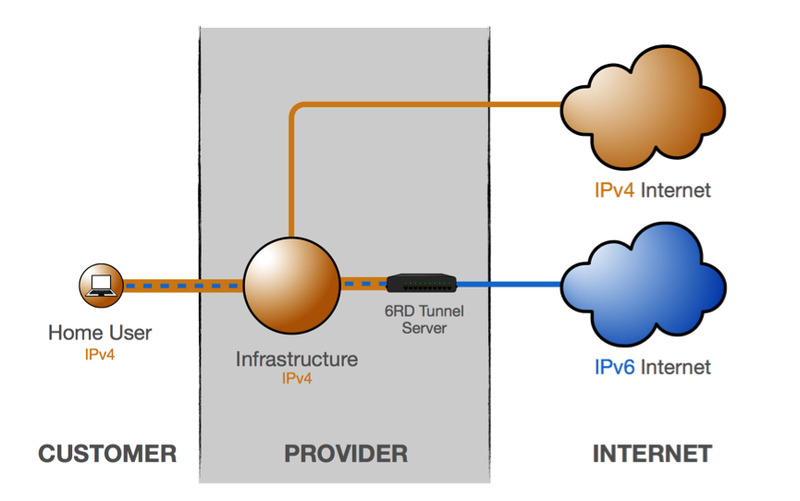
6rd
The 6rd tunneling technique was developed to fix the issues with long latencies that characterised 6to4, while maintaining scalability. 6rd has been rolled out for several million customers.
The principle behind 6rd tunneling is similar to that of 6to4, with the main difference being that the ISP's IPv4 and IPv6 address space is used for the tunnel endpoints. This means anycast is no longer used, and traffic is symmetrical and controlled by the ISP.
Just like with 6to4, the IPv4 addresses of the tunnel endpoints have to be embedded in the IPv6 address of the end user device. Since the first 32 bits of the end user device's IPv6 address will be taken up by the ISP's prefix and the second 32 bits will be the embedded IPv4 address of the tunnel endpoints, only one /64 IPv6 range is available for each device.

Requesting a larger allocation of address space (a /29 instead of a /32) would mean three more bits, which equals eight IPv6 subnets that can be assigned to each end user device, instead of just one.

You can also choose to embed only the variable part of your IPV4 address in the 6rd IPv6 address. If you are using a /21 IPv4 allocation, that would mean embedding only the variable bits – the last 11 bits (32-21 = 11bits) – instead of embedding all 32 bits of the IPv4 address.

Combining both measures (requesting a /29 IPv6 allocation and only using the variable bits of the IPv4 address) gives us the following:

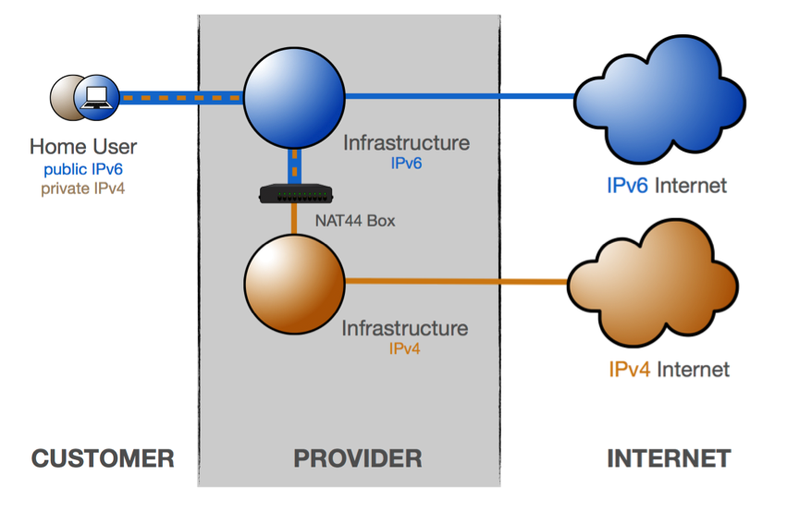
DS-lite
In contrast to all the other transitioning mechanisms discussed above, DS-lite encapsulates IPv4 packets in IPv6 packets, resulting in the tunneling of IPv4 over IPv6. This is just the opposite of all the other transitioning techniques discussed.
DS-lite enables an IPv6 device to connect to IPv4 devices and the IPv4 Internet.
The main purpose of DS-lite is for the ISP to avoid deploying a public IPv4 address to the customer's Customer Premises Equipment (CPE). Instead, only global IPv6 addresses are assigned.
The CPE distributes private IPv4 addresses for the clients – the same as a NAT device. However, instead of performing the NAT itself, the CPE encapsulates the IPv4 packet inside an IPv6 packet. The CPE uses its global IPv6 connection to deliver the packet to the ISP's carrier-grade NAT (CGN), which has a public IPv4 address. The IPv6 packet is decapsulated, restoring the original IPv4 packet. NAT is performed on the IPv4 packet and it is routed to the public IPv4 Internet.
2. Translation
In the case of translation, the IPv6 packet is not encapsulated in an IPv4 packet. Rather, the IPv6 header of the packet is replaced by an IPv4 header: so the IPv6 packet is converted into an IPv4 packet.
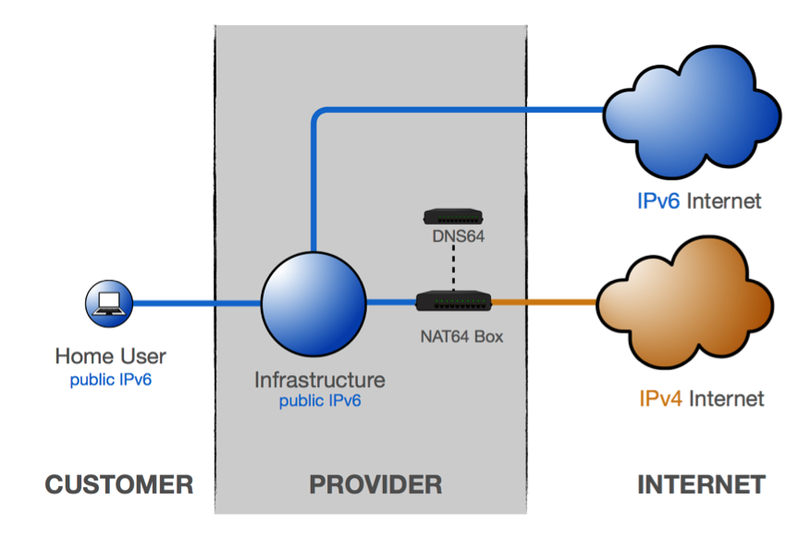
NAT64/DNS64
NAT64/DNS64 is a technique that makes it possible for IPv6-only clients to talk to IPv4 devices.
In the provider's domain there is a translator box (Nat64 server) that strips the IPv6 headers off the packets and replaces them with IPv4 headers. The NAT64 server is the endpoint for at least one IPv4 address and an IPv6 network segment of 32-bits (for example, 64:ff9b::/96).
The central part of this mechanisms is DNS64. In the case of DNS64, the DNS server converts IPv6 DNS queries into IPv4 DNS queries, and then converts the received answers (the IPv4 DNS records) into IPv6 records, which can be interpreted by the IPv6-only device.
NAT64/DNS64 is used by large mobile providers.
One issue is that some mobile phone apps are only supported over IPv4 and are not IPv6 capable.
To solve this issue, an additional transition mechanism called 464XLAT is used in combination with NAT64/DNS64. 464XLAT works by installing software (CLAT demon) on the IPv6 mobile device.
464XLAT gives the mobile device a dummy (private) IPv4, so the IPv4-only applications can now work with an IPv4 address, and the demon translates locally on the mobile to IPv6.
Conclusion
Any transitioning technique adds complexity and requires more network management and should be avoided if possible.
Dual stacking your entire network is the preferable solution if possible.
Further Reading:
- IPv6 Transition Mechanisms – Videos (RIPE NCC)
- A Comparison of IPv6 over IPv4 Tunnel Mechanisms (IETF Internet-Draft)
- Case Study: T-Mobile US Goes IPv6-only Using 464XLAT (Internet Society)